Eine eigene Datenplattform für Alle
Heutzutage sucht jeder einen Ort für Daten an dem, Informationen gewonnen, geteilt und visualisiert werden können. Datenplattformen kümmern sich genau um diese Problemstellung. Als EFS sind wir in dem Themenfeld seit über 10 Jahren unterwegs und haben eines gemerkt bei jeder Datenplattform sind es die gleichen Herausforderungen:
- Welche IT-Infrastruktur wird genutzt
- Wie können Daten hochgeladen werden
- Wie können die Daten durchsuchbar gemacht werden
- Welche Metadaten sind zu den Daten vorhanden
- Wie können die Metadaten gespeichert und ein Suchindex generiert werden
- Wie werden die Daten visualisiert
- Wie kommunizieren die Plattformservices untereinander
- Wie können IoT-Devices angebunden werden
- Rollen und Rechte
- Datenweiterverarbeitung (Virtuelle Maschinen, Cluster on Demand)
- DSGVO
Also warum diese grundlegenden Probleme nicht einmal lösen und auf Basis der Plattform Innovationen voranbringen?
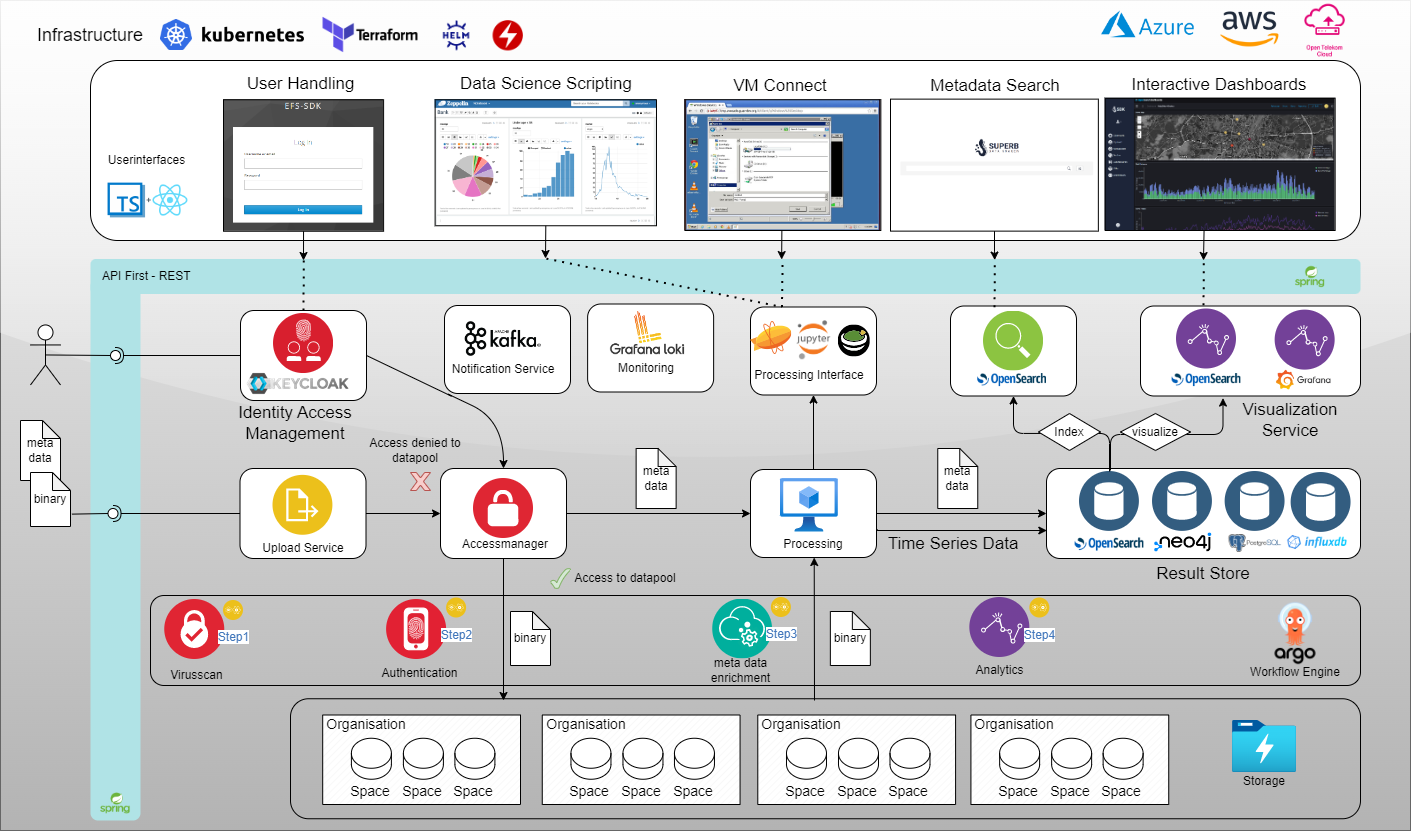
Deshalb wollen wir eine Plattform schaffen für jeden
Wir nutzen viele Open Source Frameworks und geben das Ergebnis auch wieder in Form von Open Source an die Welt zurück. Sobald die Plattform eine Reife erreicht hat die wir veröffentlichen können. Alle Services werden als Infrastructure as Code entwickelt, so dass sich jeder seine eigene Plattform einrichten kann!
Was wurde bisher Implementiert:
- Automatisches zur Verfügung stellen einer IT-Infrastruktur (AWS, Azure, OTC, lokal)
- Workflow-Engine (Alle Automatisierungen werden von Beginn an mit Workflows realisiert)
- Suchindex (Metadaten werden in einem Opensearch Cluster gehalten)
- Datenvisualisierung mit Kibana, Grafana
- Uploadclient
- Authentifzierungsservice
UseCase Große Dateien im System ablegen und analysieren
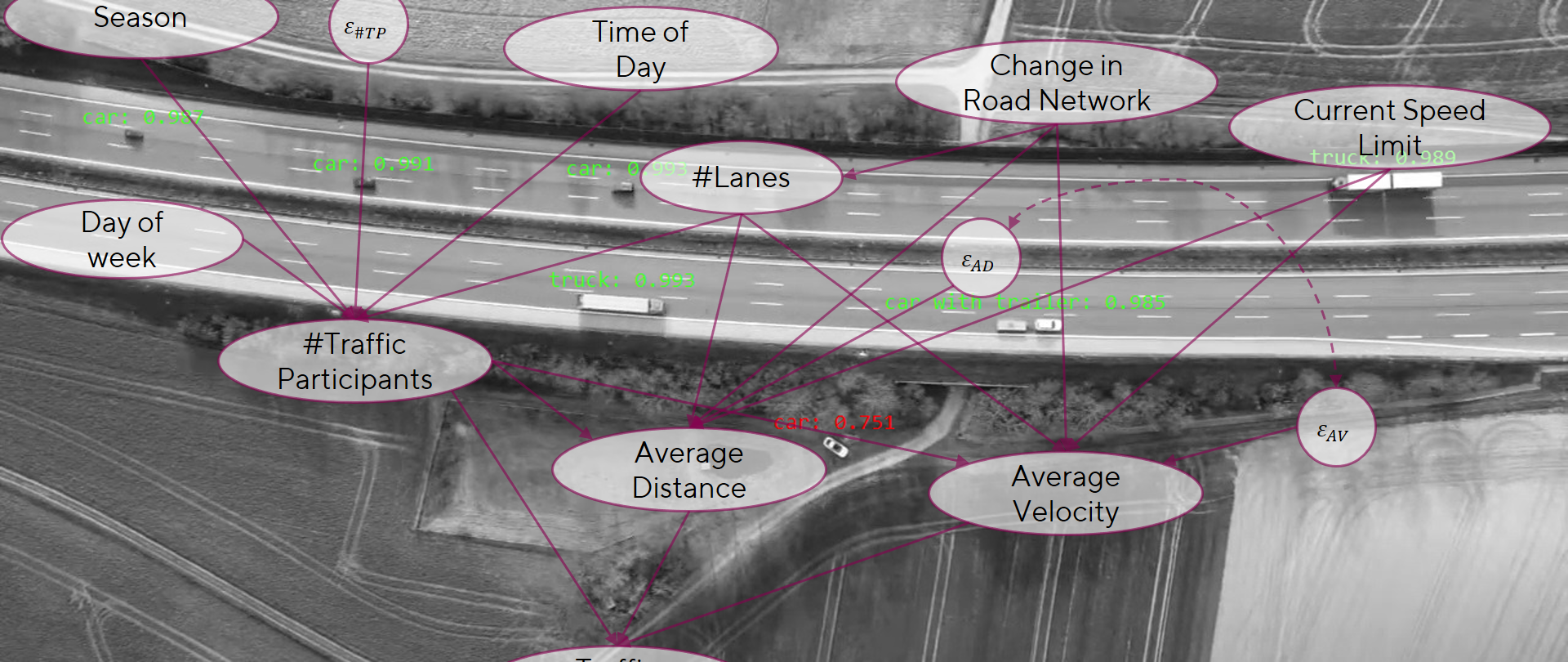
Jeder Datensatz besteht aus den Daten die man über eine Plattform bereitstellen möchte und den Metadaten zu den Daten. Über eine Upload-App können Daten in die Verarbeitungszone der Plattform hochgeladen werden. Hierfür muss eine Authentifizierung gegen einen Keycloack Server erfolgen. Ist der Nutzer berechtigt die Daten hochzuladen werden diese in der Verarbeitungszone gespeichert. Sobald die Daten fertig hochgeladen sind läuft ein Workflow los, welcher die Metadaten auswertet. Anhand der Metadaten wird entschieden, welche weitere Verarbeitungslogik angestoßen wird.
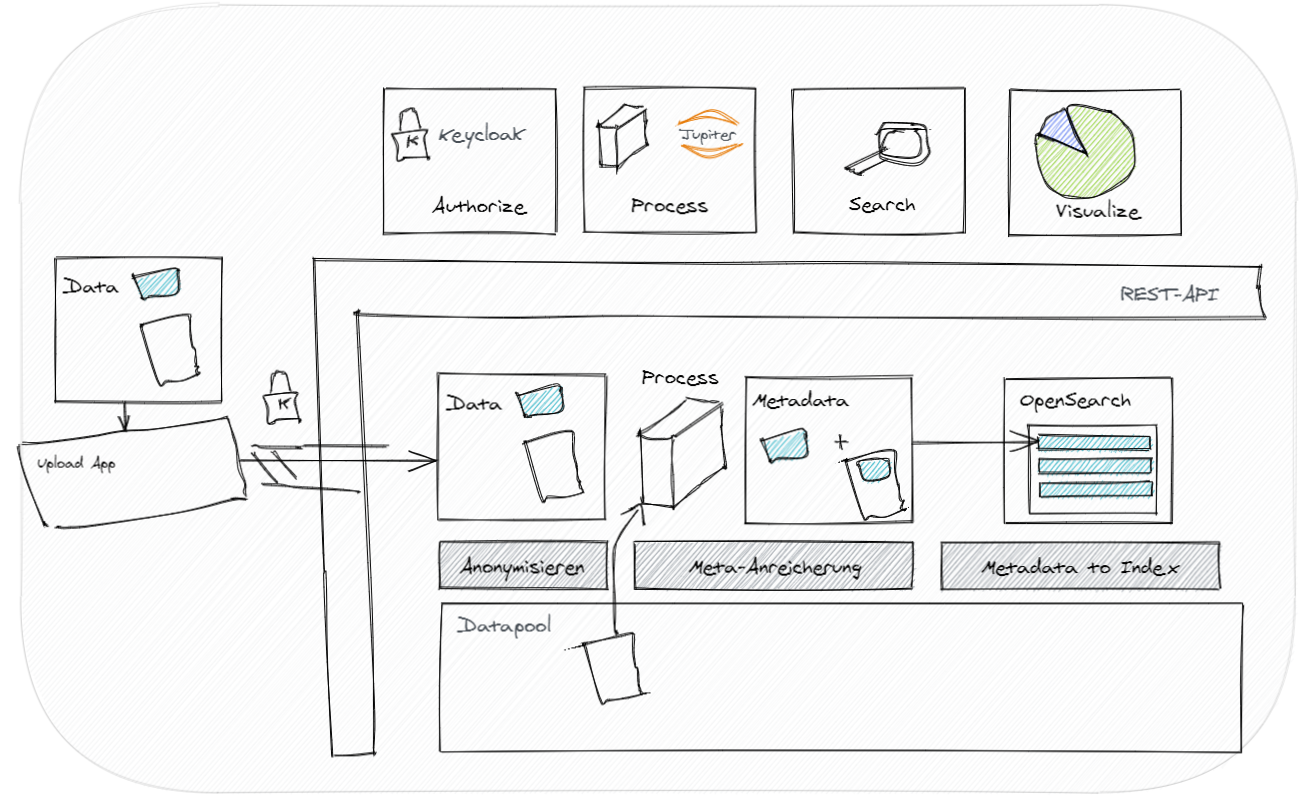
Die Abbildung zeigt einen Beispielworkflow für Daten in der EFS-SDK. Sobald die Daten in der Verarbeitungszone angekommen sind werden die Informationen anonymisiert. Namen werden aus den Metadaten entfernt und einer abstrakten ID zugewiesen. Im zweiten Schritt werden Metainformationen aus den zusätzlich zur Verfügung gestellten Datensätzen extrahiert. Dies geschieht im Processing Service, welcher Beispielsweise eine VM oder einen Docker zur Verfügung stellt um die Verarbeitungslogik auszuführen. Anschließend werden die Daten selbst in den eigentlichen Zieldatenpool verschoben. Die Metainformationen werden in den OpenSearch kopiert und im Suchindex aufgenommen. Damit wird eine google-like Suche ermöglicht um die Datensätze wieder zu finden.
Zur Visualisierung wird Kibana verwendet. Hier können Daten aus OpenSearch dargestellt und aggregiert werden. Um Inhalte der im Datenpool abgelegten Datensätze visualisieren zu können, kann eine Analyse in der Plattform durchgeführt werden. Hierfür stehen die Möglichkeiten zur Verfügung ein Virtuelle Maschine zu provisionieren oder bei größeren Analysen einen Spark Cluster zu provisionieren um Analysen durchzuführen.
In einer virtuellen Maschine wird eine Windows oder Linux Maschine zur Verfügung gestellt. Nutzer können dort die bereits gewohnten Analysetools installieren, die bereits zuvor auf lokalen Rechner verwendet wurden. Über Remote-Desktop kann auf die Maschinen zugegriffen werden. Sind große Mengen an Daten gleichzeitig zu verarbeiten, kann auch ein Spark Cluster hochgefahren werden, um dort eine Big Data Analyse durchzuführen. Auf dem Cluster kann mit Jupiter Notebooks die Analyse umgesetzt werden.
Die hierbei entstehenden KPIs oder Zeitreihen werden in einem OpenSearch Index abgelegt und anschließend in Live-Dashboards visualisiert. Regelmäßig wiederkehrende Analysen können in einen Workflow überführt werden. So können neue Daten die einem bestimmten Pattern entsprechen automatisch analysiert werden und dem Live-Dashboard hinzugefügt werden.
Interesse Innovationen schneller zu erreichen? – Dann lasst uns drüber reden wie wir voneinander lernen können!